Today was very successful as we finally were able to finish debugging the script we were using for training our experiment models. Previously, I was seeing the loss function diverge to nan during the second batch and the problem was actually that I was forgetting to shuffle the data with each new batch. After cleaning up much of the script, I was able to organize the code to be more general purpose for future experiments.

I ran the new code to train an offline so i could generate some baseline numbers to use for omega values for the experiments. However, I am still adjusting a few hyperparameters (namely the patience counter for early stopping to prevent overfitting) to see what will yield the highest offline accuracy with bounding boxes implemented.
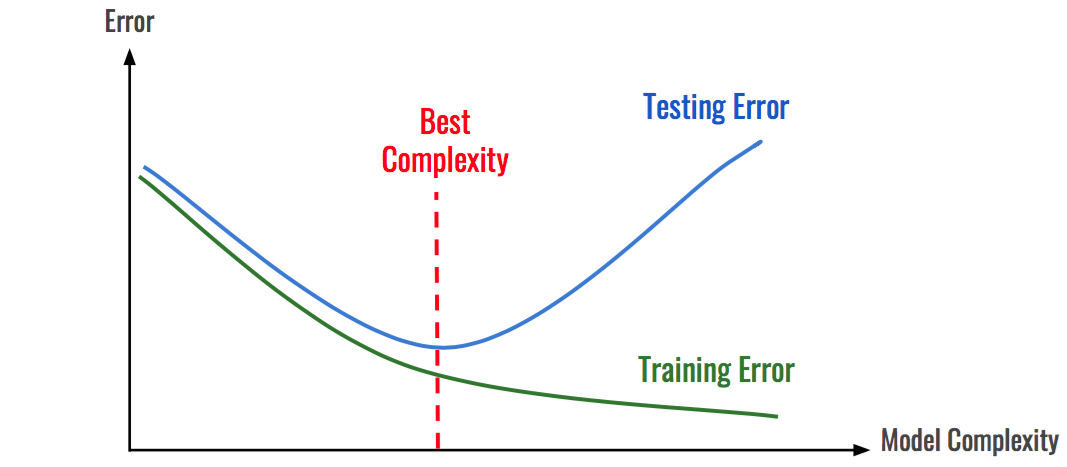
The full rehearsal model was fairly simple to implement after the offline model trained so I plan to start evaluating Mahalanobis OOD and more complex models tomorrow.
I ran the new code to train an offline so i could generate some baseline numbers to use for omega values for the experiments. However, I am still adjusting a few hyperparameters (namely the patience counter for early stopping to prevent overfitting) to see what will yield the highest offline accuracy with bounding boxes implemented.
The full rehearsal model was fairly simple to implement after the offline model trained so I plan to start evaluating Mahalanobis OOD and more complex models tomorrow.
Comments
Post a Comment