Today I took a step forward toward a more specific focus on machine learning and neural networks. After quickly reviewing yesterday's material through Datacamp exercises on python and Numpy, I spent most of the morning completing tutorials on implementing various classifiers using the machine learning software Scikit-learn.

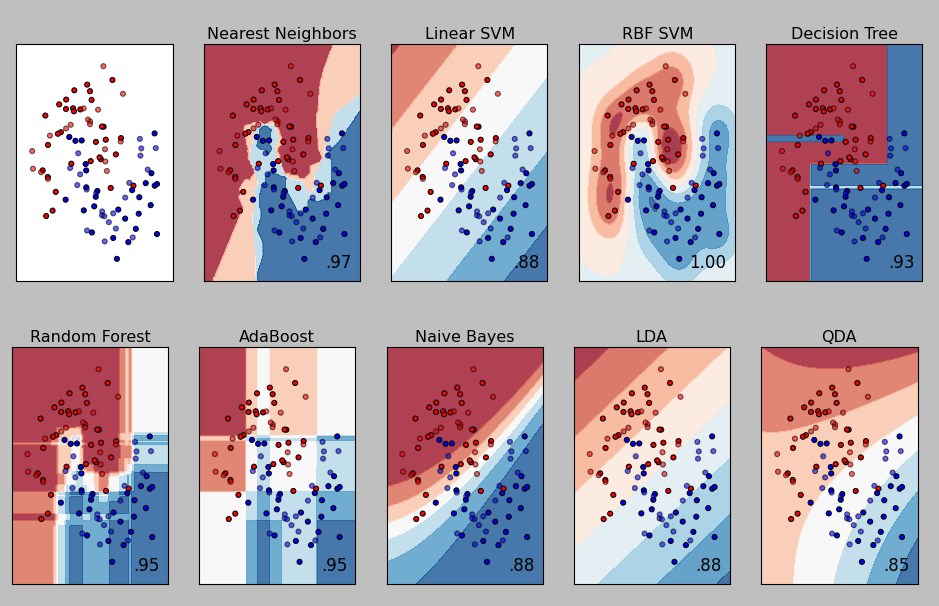
First using the simple K Nearest Neighbors Classifier, I learned how to fit classifiers to data, use the classifiers to predict targets for new test data, and evaluate the accuracy and errors of each classifier using Confusion Matrices and Classification Reports. Then, I applied what I learned to both the Iris (classifying three types of flowers) and MNIST (classifying handwritten digits) datasets implementing different types of models such as Support Vector Machine (both Linear and RBF), Gaussian Process, and Multilayer Perceptron Classifiers.
In the afternoon, I watched a Youtube playlist which provided an introduction to neural networks including a basic Python implementation of Linear Regression. After finishing that simple neural network, I started learning more specifically about Convolutional Neural Networks (CNNs), especially used in computer vision problems. With guidance from resources such as Stanford's CS231 and RIT's Deep Learning for Vision courses, I hope to be able to implement CNNs in code later this week.
First using the simple K Nearest Neighbors Classifier, I learned how to fit classifiers to data, use the classifiers to predict targets for new test data, and evaluate the accuracy and errors of each classifier using Confusion Matrices and Classification Reports. Then, I applied what I learned to both the Iris (classifying three types of flowers) and MNIST (classifying handwritten digits) datasets implementing different types of models such as Support Vector Machine (both Linear and RBF), Gaussian Process, and Multilayer Perceptron Classifiers.
In the afternoon, I watched a Youtube playlist which provided an introduction to neural networks including a basic Python implementation of Linear Regression. After finishing that simple neural network, I started learning more specifically about Convolutional Neural Networks (CNNs), especially used in computer vision problems. With guidance from resources such as Stanford's CS231 and RIT's Deep Learning for Vision courses, I hope to be able to implement CNNs in code later this week.
Comments
Post a Comment