I started off today by reading a few papers written on topics related to my project of combining open set recognition with incremental learning. I understand the goals and challenges associated with creating a CNN with these capabilities but am not yet sure exactly how I will implement them concretely in a model to experiment with.
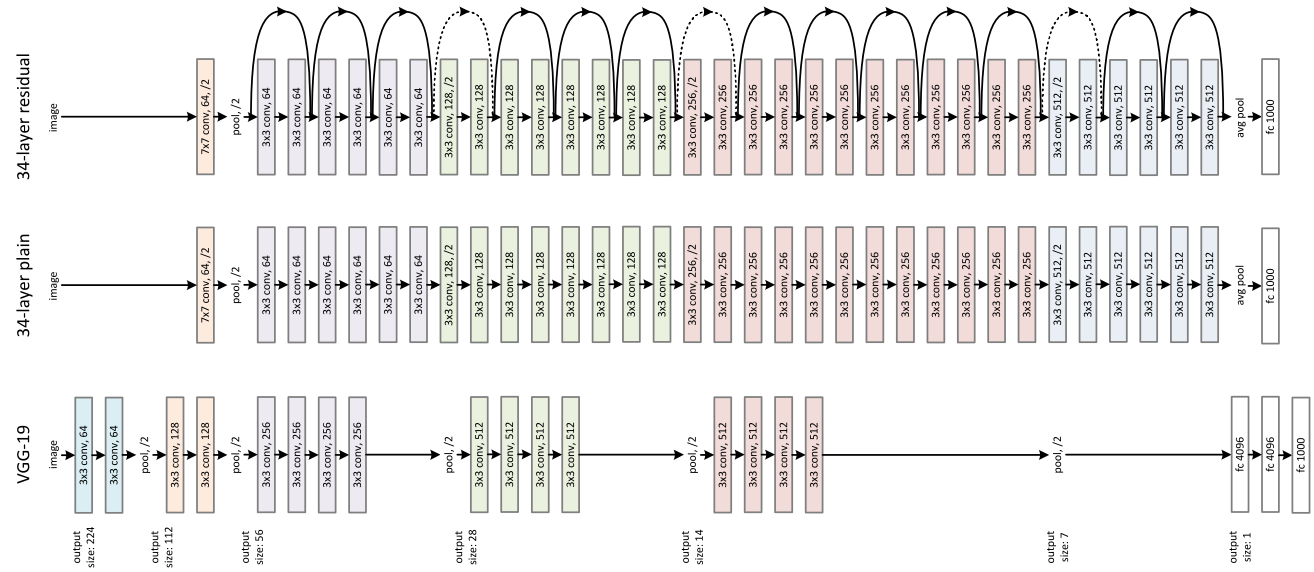
The rest of the morning I spent going through Andrew Ng's course on Convolutional Neural Networks. I feel like I learned a lot regarding how convolutions work, how to control padding and stride, and understanding the structure of notable case studies such as the LeNet-5, AlexNet, VGGNet, and ResNet. These open-source networks are helpful places to start when I implement my own CNNs because they have already chosen decent hyperparameters which could then be fine-tuned to fit a specific problem.
Around noon, the other interns and I listened to a seminar given by David Messinger on how hyper spectral imaging can be used to learn about artifacts like the Gough Map of Great Britain. It was a very interesting talk and was well worth it to attend (the free pizza was an added plus).
After lunch, I wrote my problem statement / part of my abstract for the openset incremental learning project I will begin soon. Here is the link to that draft paper:
Incremental Open Set Recognition: Exploring Novel Input Detection in Incremental Learning Models
Finally, I spent the rest of the day playing around with creating and training CNNs with the Pytorch module. I made a small network with a few convolutions and pooling layers which eventually fed into three fully connected layers. Using a Cross Entropy Loss Function and Stochastic Gradient Descent during training to optimize the weighted parameters, here were the model's results testing on the CIFAR-10 dataset:

The rest of the morning I spent going through Andrew Ng's course on Convolutional Neural Networks. I feel like I learned a lot regarding how convolutions work, how to control padding and stride, and understanding the structure of notable case studies such as the LeNet-5, AlexNet, VGGNet, and ResNet. These open-source networks are helpful places to start when I implement my own CNNs because they have already chosen decent hyperparameters which could then be fine-tuned to fit a specific problem.
Visualization of VGG-19 vs. Plain Network vs. Residual Network structure
Around noon, the other interns and I listened to a seminar given by David Messinger on how hyper spectral imaging can be used to learn about artifacts like the Gough Map of Great Britain. It was a very interesting talk and was well worth it to attend (the free pizza was an added plus).
After lunch, I wrote my problem statement / part of my abstract for the openset incremental learning project I will begin soon. Here is the link to that draft paper:
Incremental Open Set Recognition: Exploring Novel Input Detection in Incremental Learning Models
Finally, I spent the rest of the day playing around with creating and training CNNs with the Pytorch module. I made a small network with a few convolutions and pooling layers which eventually fed into three fully connected layers. Using a Cross Entropy Loss Function and Stochastic Gradient Descent during training to optimize the weighted parameters, here were the model's results testing on the CIFAR-10 dataset:
Accuracy of the network on the 10000 test images: 58 %
Accuracy of plane : 67 %
Accuracy of car : 82 %
Accuracy of bird : 45 %
Accuracy of cat : 29 %
Accuracy of deer : 56 %
Accuracy of dog : 55 %
Accuracy of frog : 66 %
Accuracy of horse : 58 %
Accuracy of ship : 75 %
Accuracy of truck : 47 %
Four sample CIFAR-10 images of model's predicted labels vs. ground truth labels

GroundTruth: cat ship ship plane
Predicted: cat ship ship ship
This network is clearly not ideal for classifying these images (at only 58% accuracy overall), but I am excited to start exploring transfer learning and practice implementing pre-trained effective networks next week.
Comments
Post a Comment