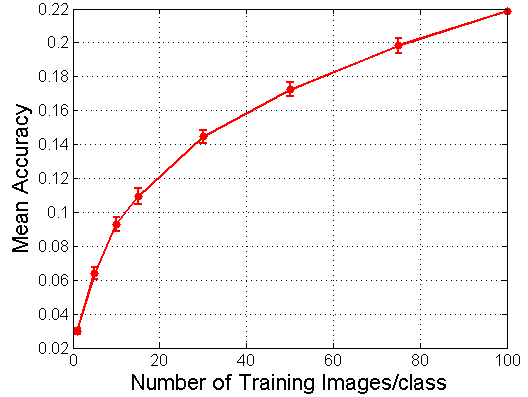
Today I continued my work with transfer learning from yesterday and applied it to new data: the Stanford Dogs dataset. This contains images representing 120 different species of dogs, and I trained a model to classify them that was similar to the one I used for CUB-200. I realized an error I was doing before was computing the Cross Entropy Loss as well as passing the weights of the fully connected through a Log Softmax function. As a result, I was actually computing the log of the weights twice which was affecting the training of my model's parameters. After fixing that structure, I achieved ~83% accuracy classifying the dog species using fixed feature extraction on Resnet18, although I hope to still improve in the future. There are a number of hyperparameters I can play around with such as the transformations for data augmentation, the learning rate for the criterion, the criterion and optimizer functions themselves, the batch size of the training samples, etc.

Along with tweaking the hyperparameters, I practiced implementing different models (e.g. Resnet152, VGG16) and also figured out how to save and load models that I already trained on my datasets. Finally, I spent some time practicing being able to manipulate the datasets and extract information about them. This included, extracting the class names, plotting a batch of sample images with class labels, graphing the distribution of image samples per class, and creating other statistical plots as well.

Tomorrow I hope to take the knowledge I have learned from transfer learning and apply it to conduct incremental learning or open set recognition experiments. This will allow me to draw conclusions regarding the effect each aspect of lifelong learning has on the other when implemented as one model.
Along with tweaking the hyperparameters, I practiced implementing different models (e.g. Resnet152, VGG16) and also figured out how to save and load models that I already trained on my datasets. Finally, I spent some time practicing being able to manipulate the datasets and extract information about them. This included, extracting the class names, plotting a batch of sample images with class labels, graphing the distribution of image samples per class, and creating other statistical plots as well.
Tomorrow I hope to take the knowledge I have learned from transfer learning and apply it to conduct incremental learning or open set recognition experiments. This will allow me to draw conclusions regarding the effect each aspect of lifelong learning has on the other when implemented as one model.
Comments
Post a Comment