Today I tested the previously trained models using the Stanford dogs dataset as the inter dataset evaluator for OOD instead of the Oxford flowers dataset. However, as expected, the omega values for performance were pretty much the same as before and didn't make much of a difference as the datasets varied.
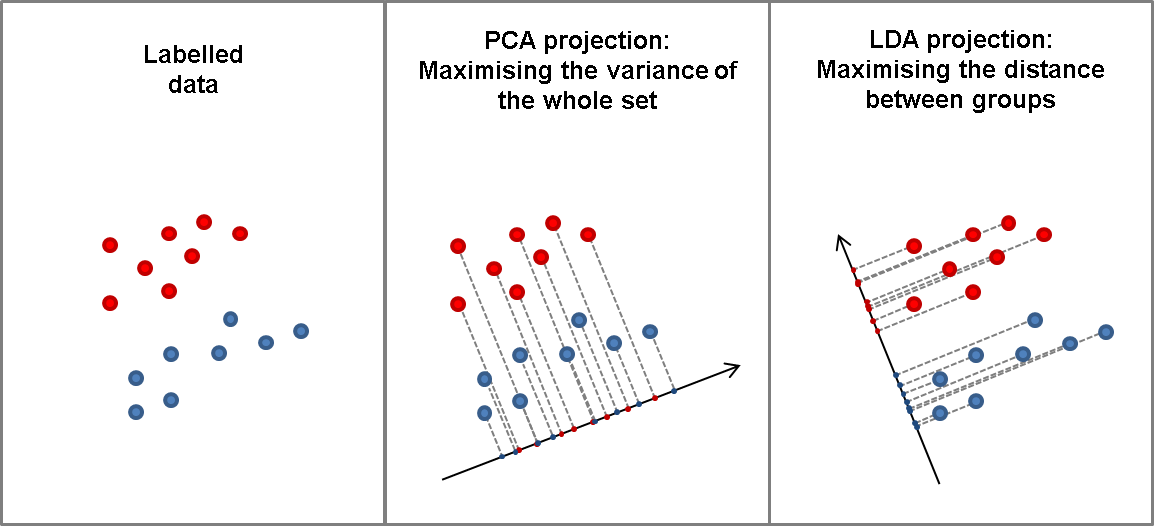
I also implemented a streaming linear discriminant analysis model (SLDA) which differed from the previous incrementally trained models. This model didn't perform as well in terms of accuracy however as only the last layer of the model was trained and streaming is more of a difficult task. Nevertheless, we did show that Mahalanobis can be used in a streaming paradigm to recover some OOD performance in an online setting. This is likely to be a large focus of my presentation as it has never been discussed prior.
Tomorrow, I plan to implement an L2SP model with elastic weight consolidation as well as iCarl to serve as two more baselines to compare our experiments to.
Comments
Post a Comment